TeleHash is a new wire protocol for exchanging JSON in a real-time and fully decentralized manner, enabling applications to connect directly and participate as servers on the edge of the network. It is designed to efficiently route and distribute small bits of data in order for applications to discover each other directly or in relation to events around piece of shared content. The core benefits of TeleHash over other similar platforms and protocols is that it is both generic (not tied to any specific application or content structures) and is radically decentralized with no servers or points of central control.
It works by sending and receiving very simple small bits of JSON via UDP using an easy routing system based on Kademlia, a proven and popular Distributed Hash Table. Everything within TeleHash is routed based on a generic SHA hash, usually of something specific to an application or something common like a URL.
While it is still young, the protocol and early implementations are evolving quickly and can already be used. Everyone is welcome to start experimenting and get involved in any form.
http://telehash.org/
Thursday, May 27, 2010
Cross-Origin Resource Sharing (CORS)
Cross-Origin Resource Sharing (CORS) is a W3C Working Draft that defines how the browser and server must communicate when accessing sources across origins. The basic idea behind CORS is to use custom HTTP headers to allow both the browser and the server to know enough about each other to determine if the request or response should succeed or fail.
http://www.nczonline.net/blog/2010/05/25/cross-domain-ajax-with-cross-origin-resource-sharing/
http://www.nczonline.net/blog/2010/05/25/cross-domain-ajax-with-cross-origin-resource-sharing/
Tuesday, May 18, 2010
Get xpath string expression of a document element
XPath is one of those things you don’t hear too much about these days. In the days when XML ruled, XPath was very important to developers as a means of random access within a large structure. Since JSON was popularized, XPath has gotten less and less attention, but there is still fairly good support for XPath queries in browsers.
http://snippets.dzone.com/posts/show/3754
function getElementXPath(elt) { var path = ""; for (; elt && elt.nodeType == 1; elt = elt.parentNode) { idx = getElementIdx(elt); xname = elt.tagName; if (idx > 1) xname += "[" + idx + "]"; path = "/" + xname + path; } return path; } function getElementIdx(elt) { var count = 1; for (var sib = elt.previousSibling; sib ; sib = sib.previousSibling) { if(sib.nodeType == 1 && sib.tagName == elt.tagName) count++ } return count; }http://www.nczonline.net/blog/2009/03/17/xpath-in-javascript-part-1/
http://snippets.dzone.com/posts/show/3754
Sunday, May 9, 2010
Awesome Print
awesome_print is a Ruby tool that provides "pretty printing" support for your objects. It's a bit like
Being able to see "inside" Ruby objects on the fly can prove useful whether you're debugging some code your tests did not dare reach or you're just playing around in
A visual comparison between
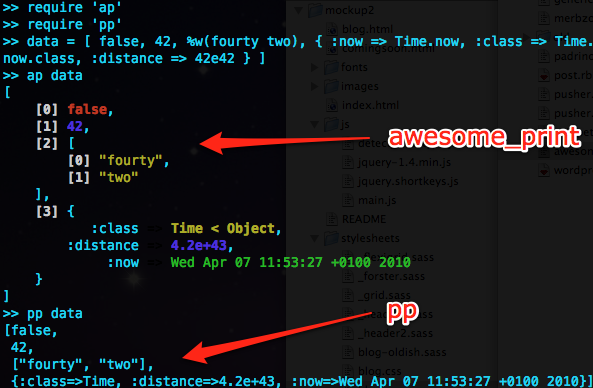
awesome_print's most compelling features are showing you the index of array elements within its output, inheritance for the classes of embedded objects, and color coding. Further, it's highly customizable, with the ability to set indent levels as well as the colors for each type of data shown.
To get up and running,
http://github.com/michaeldv/awesome_print
http://www.rubyinside.com/awesome_print-a-new-pretty-printer-for-your-ruby-objects-3208.html
p, pp or, if you prefer, puts obj.inspect, but with significantly improved, contextual, colored output. Its creator and maintainer is Michael Dvorkin of Fat Free CRM fame. Being able to see "inside" Ruby objects on the fly can prove useful whether you're debugging some code your tests did not dare reach or you're just playing around in
irb. The most common way to examine objects is with p or the inspect method, but these don't format their output in a particularly easy-to-read way. pp - part of the standard library - is a pretty printer that improves matters but it still leaves a lot to be desired. awesome_print takes it all to the next level.A visual comparison between
pp and awesome_print proves compelling:awesome_print's most compelling features are showing you the index of array elements within its output, inheritance for the classes of embedded objects, and color coding. Further, it's highly customizable, with the ability to set indent levels as well as the colors for each type of data shown.
To get up and running,
gem install awesome_print and then require 'ap' and use ap in place on anywhere you'd usually use p. Yep, that's it.http://github.com/michaeldv/awesome_print
http://www.rubyinside.com/awesome_print-a-new-pretty-printer-for-your-ruby-objects-3208.html
Wednesday, May 5, 2010
RGraph: HTML5 canvas graph library based on the HTML5 canvas tag

Microsoft Internet Explorer 8 is now (December 2009) supported in a limited fashion. You can read more about it here.
Older versions of Opera and other older browsers are supported in a limited fashion. If they don't support text or shadows these will naturally be unavailable.
- Introduction to RGraph
- Benefits of HTML5 canvas graphs
- Examples & documentation
Bar chartBi-polar chartDonut chartFunnel chartGantt chartHorizontal Bar chartLED gridLine chartMeterOdometerPie chartProgress barRose chartScatter chartTraditional radar chart
- Browser support
- Improving the performance of your graphs
- Implementing RGraph
- Suggested structure for RGraph
- Integration with server side scripting
- Common issues
- Support forum
- Download
http://www.rgraph.net/
Sunday, May 2, 2010
Find duplicates in an Array with grep
The following example finds duplicates in an array by selecting all array items which have apear more than once.
a = %w(a b a c) a.uniq.select {|x| a.grep(x).length > 1} #=> ["a"] a = %w(a b a c d d d e f g h f) a.uniq.select {|x| a.grep(x).length > 1} #=> ["a", "d", "f"]
a = %w(a b a c d d d e f g h f) a.group_by(&:to_s).select{|k,v| v.length > 1} #=> {"a"=>["a", "a"], "d"=>["d", "d", "d"], "f"=>["f", "f"]}http://snippets.dzone.com/posts/show/11219
Subscribe to:
Comments (Atom)